Data Craze Weekly #6

This message was sent first to subscribers of Data Craze Weekly newsletter.
Week in Data
What is Modern Data Stack
Ding, ding, ding! Buzzword detected. Modern Data Stack is probably the most popular phrase in the data world recently.
What does it really come down to?
Basically, to create such an architecture and data processing method that would provide end users with what they expect, e.g. almost real-time processing, good performance, data availability, etc.
The author interestingly goes through the defined elements of the Modern Data Stack, describing in general (without directly imposing specific tools) what is worth paying attention to.
If this definition has appeared in your circle of information, this article will allow you to logically arrange all the blocks related to the Modern Data Stack.
Link: https://medium.com/@bengoswami/how-to-build-a-morden-data-stack-378afbe04c2d
AirBnB Data Warehouse Update
A slightly more technical article, going down to the level of data storage.
What steps did AirBnB engineers take to improve the efficiency of their warehouse?
If you are interested in:
- Apache Iceberg
- Apache Spark 3.0
- AQE (Adaptive Query Execution) in Spark
and why these changes improved performance in the case of AirBnB (lest they are a panacea always and for everything), please see the link below.
And here are some general conclusions:
Comparing the prior TEZ and Hive stack, we see more than 50% compute resource-saving and 40% job elapsed time reduction in our data ingestion framework with Spark 3 and Iceberg. From a usability standpoint, we made it simpler and faster to consume stored data by leveraging Iceberg’s capabilities for native schema and partition evolution.
Link: https://medium.com/airbnb-engineering/upgrading-data-warehouse-infrastructure-at-airbnb-a4e18f09b6d5
The 5 most popular SQL queries
Warning, a bit of clickbait… The 5 most popular SQL queries are actually based on queries created in the SQL Generator 5000 tool (more about which in the tools section).
Nevertheless, it is interesting to check what people click most often, and these are:
- Correlations (CORR function in SQL)
- Data cleaning (in the tool as CLEAN, but underneath it is a set of various functions, e.g. COALESCE, CAST, etc.)
- JOIN 🙂
- Pivot tables (PIVOT – if you can turn something into Excel, why not use it)
- Aggregates – a set of functions aggregating data (e.g. MAX, SUM, COUNT)
Author’s conclusions:
SQL Generator is more popular for automating tedious SQL rather than complex logic
– SQL usage is diverse — in other words, we can’t just learn 5 things and suddenly become experts.
We are all looking for the same thing, no matter if we have been working with SQL for a month or 10 years 🙂
Link: https://towardsdatascience.com/the-5-most-popular-sql-transforms-ca1f977ef2b2
How to catch up on 5,500 hours of podcasting with AI
How do you make up for 5,500 hours of a podcast that also releases several hours of new material each week?
The author of the attached article, Enias Cailliau, had such a puzzle.
Using, among others, NLP (Natural-Language-Processing) algorithms, transformed the audio tracks of Joe Rogan’s podcast into text, which he further processed. By creating correlations or assessing the tone (positive/negative).
How did he do it technically? Check the article.
Link: https://medium.com/steamship/im-consuming-5000-hours-of-joe-rogan-with-the-help-of-ai-9cb7cc7a4985
Tools
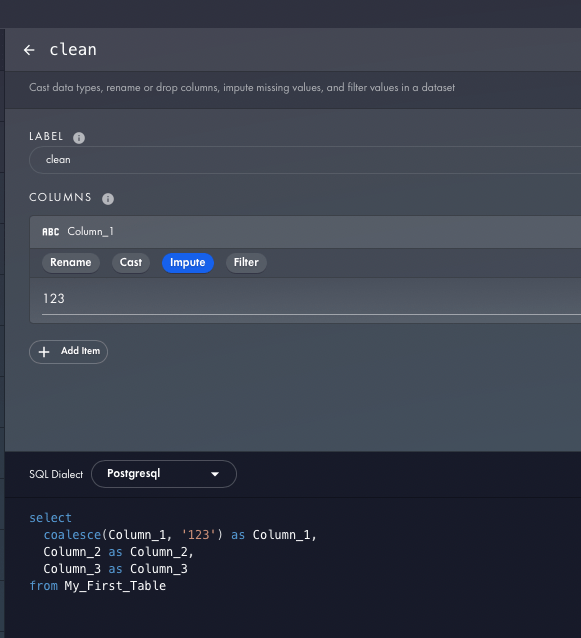
SQL Generator 5000 – a tool that will help you easily generate popular SQL queries, e.g. aggregates, pivot tables, etc.
- Create a data schema (DDL with a table)
- Select SQL syntax (ready-made from the list)
- Complete and click Generate SQL
SQL Generator 5000 example:
Link: https://app.rasgoml.com/sql
Check Your Skills
#SQL
Using the WITH RECURSIVE syntax, find all previous IDs for ID “e”. Where the relationship previous -> new is defined as follows.
Table: derived_from, Columns: id_previous, id_new.
Lines: id_previous: a, id_new: b id_previous: g, id_new: c id_previous: c, id_new: d id_previous: d, id_new: e
Solution: https://sqlfiddle.com/#!17/14f08/1
More SQL related questions you can find at SQL - Q&A
Data Jobs
- Backend Engineer (Python), SIZZLE – Remote EU / North America – USD 50,000 – USD 150,000
Skills sought: SQL, Python, Spark
- Junior ETL Developer, GreenMinds – Fully Remote – PLN 12,600 – PLN 14,280 (net/month, B2B)
Skills sought: SQL, Python, Spark