What Is Data Engineering

Start with the definition of data engineering, copy-paste from Wikipedia, or maybe tell my story and how, purely subjectively, I perceive this topic?

There will be history, but before we go back a few years, I will tell you what you will take away from this article:
- you will learn what data engineering is
- what could be one of the paths leading to the role of Data Engineer
- you will learn the fields (groups) of data engineering in which you can specialize
- I will show you what is “hot” in the world of data at the moment (2020).
- how not to get lost in the jungle of slogans, technologies and abbreviations
Earlier, I published an entry on the blog, How To Start Your Career In Data, in which I also wrote about data engineering. Don’t worry, this post won’t be a carbon copy. From there, you’ll learn about general concepts, useful resources, and people to follow. I am creating this entry with the intention of providing a full-fledged introduction to data engineering.
My Story
Okay, now that we have the long introduction behind us, let’s go back 10 years, it’s 2010, the term Data Engineer was crawling, not to say that it simply didn’t exist.
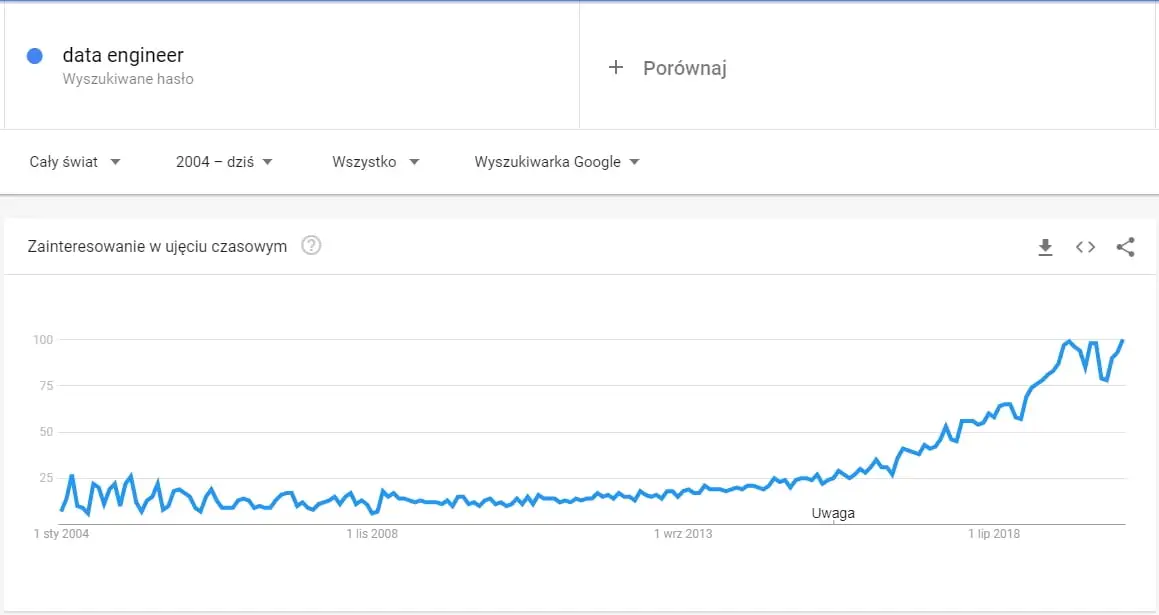
Trend for the phrase data engineer since 2004, based on data from Google Trends
10 years have passed…
I would like to introduce you to… me, 10 years younger, studying Computer Science at the Krakow University of Technology, not yet fully aware of what I want to do after graduation, but it will definitely be “IT”. There was no money transfer at that time, it was hard to find a banknote with Mr. Jagiełło in our wallet, so we were looking for a job.
Sticking to the coined phrase “a fool is always lucky” (or if you prefer, “fortune favors the brave”), through one of the job portals I came across a job offer, i.e. an offer related to the IT field, namely - Database Programmer.
Well, I thought to myself, I know the databases, after all, we had a strong semester of learning about tuples, entities and relations. SELECT * there are no secrets from me, I’m going (like a boar into pine cones), i.e. I’m applying with the hope that my request will be positively considered. Fate and my new employer (who, nomen omen, turned out to be a great person and we maintain friendly contact to this day) wanted to give me a chance, and I didn’t want to waste this chance. And so, in accelerated mode, during the first 2 days of work, I recalled the entire semester of databases, and as I continued working, I explored the world of data (then working with the Firebird database).
STOP: how is this related to data engineering? We’ll get to that, first let me tell you what technologies and skills I used in this job:
- Databases (relational) – Firebird
- SQL
- XML
- PHP (to a small extent)
- Problem and requirements analysis
- Working directly with an external client
- Support and training after the implementation process
As you will see later in the text, most of the points above will help me in the next stages of my career and will be strongly related to the path of a data engineer
Being Consultant
Fast forward 2 years, it’s 2012, new job, this time I’m entering the world of Business Intelligence. And now to be completely honest with you, when I started I had absolutely no idea (apart from the definition from Google ;)) what BI was. I knew there were databases, SQL, data processing, reports. Generally speaking, in the world of databases and SQL I felt like a fish out of water, and since I’m not afraid of challenges (I’m a working man), I decided that if luck helps me a bit again, I’ll do everything I can to make up for any shortcomings in knowledge and help the new employer. Fortunately, this is exactly what happened, I got the opportunity to work as a Business Intelligence Consultant on a data warehouse project using Microsoft technologies and then build a warehouse from scratch based on an Oracle database and an ETL process tool also from this company - Oracle Warehouse Builder.
Okay, let’s stop for a moment, there are a few buzzwords, let’s summarize it a little (the definitions are my own, they may differ from the books):
- Business Intelligence – processes, tools and methods supporting business decisions in the enterprise.
- Data Warehouse - it is a kind of database that is organized to aggregate and store data of an enterprise or some business field of an enterprise.
- Microsoft Technology Stack - Microsoft technologies related to the world of data and Business Intelligence (at that time it was: SQL Server database, SSIS (SQL Server Integration Services) helping in data processing processes, SSAS (SQL Server Analysis Services) for building analytical processes and so-called OLAP cubes
- Oracle – provider of one of the most popular relational databases
- ETL – a data processing process characterized by downloading data from the source (Extract), transforming data in accordance with business needs (transform) and loading data to the warehouse (another database) (Load)
- Oracle Warehouse Builder – a tool for visually creating ETL processes
Working in a new company showed me that you can work with data and know little about working with data. It may sound enigmatic, but the general point is that, even apart from the world of data engineering, computer science (and probably other fields as well) is such a broad topic that if you know one element, you may be completely unaware of another element that seems to be identical (it is used to solutions to the same problems). For example, if you know databases based on Firebird, you may not know them at all from the perspective of SQL Server or Oracle. Certain foundations and concepts are the same and there is no discussion here, but the actual technological solutions may differ significantly.
STOP: is this already data engineering? Let’s not anticipate the facts slowly. What’s worth remembering from this part is:
- technologies may change, fundamental concepts and methods remain constant
- you can be a specialist in thing A, or know a little about things from A to Z
- the names of the positions may be different, but the functions and tasks in these positions are similar
Mom, Dad, I’m an engineer
Fast forward another 1.5 years, after which time I become a Software Engineer, and at least one person agrees with the title of this post.

As I had learned all the ropes in my previous work on Oracle databases (or at least that’s what I wanted to believe), I decided that this was the direction in which I wanted to develop and additionally combine it with the business world - data warehouses, business processes, analytics and visualizations. Just like before, this time it turned out that there was such an opportunity and I could take part in a project for one of the investment banks. In my daily work, I created data processing and transformation processes, which further allowed the use of data in analytical systems and the creation of a visualization layer. Visualizations and analytics, in turn, were supposed to help make good business decisions. Once again I learned how little I know and how invaluable it is to work with specialists in their field. During this period, I was able to learn and work with some of the better (at least in my opinion and knowledge) Oracle experts. I learned what good team and project management looks like. Additionally, I learned that data and processing logic tests are not a mythical unicorn and they actually exist, but if done well, they actually provide a lot of value.
STOP: Let’s quickly summarize, not yet data engineering but almost there, maybe a little timidly, what I could face:
- Oracle database
- performance challenges
- processing large (not huge) amounts of data
- data processing processes built without the need for graphical tools (scripts + database procedures)
- tests as an element of a well-functioning data warehouse
BI, love for life
We are approaching the present times, only 5 years separate us from the moment I write these words for you. Attention, the role of data engineer finally appears 🙂
To simplify the story, I decided that it would be nice to return to the world of Business Intelligence seriously, standing between hard data processing (wholesalers, etc.) and close cooperation with business, implementing business logic and building useful visualizations.
This time as a Business Intelligence Programmer, I had the pleasure of creating a data warehouse layer, as well as an analytics and visualization layer using one tool (platform) created by Qlik. It was quite a lot of fun and quite interesting problems, because you could build a separate data warehouse based on available products and separate analytics/visualization, but is it necessary?
And exactly at that time it came out, all in white… new speech, or new fashion straight from the USA, it smelled new.
What are we talking about sharing job titles in the corporate world? And so from a decent Business Intelligence Programmer I became a Data Engineer.
Have I received the knowledge of all generations of data engineers? Have my data processing skills improved 10 times… nope. Invariably, my task was to process data from the source system to the data warehouse (or another place that will play such a role), apply business logic, prepare the analytical layer and create reports or entire applications allowing the relevant departments of the company to work more easily and get “from “hands” of the necessary information.
The data guy
And finally, today (i.e. in July 2020) I have the pleasure of writing this article for you, as a data man, without titles and headings. I am trying to popularize data science, its processing, analysis and visualization, so that data is not in front of you. secrets and their conscious use helped you achieve success - however you imagine it.
Well, a dozen or so paragraphs later and there is still no definition of data engineering and no description of the role of a data engineer.
So what is this magical data engineering, or is it just a title given by the reigning HR director, and tomorrow it will be called something completely different? Let’s forget about the jokes and focus on the features of the role.
What is data engineering?
To start off on a strong footing, take a look at the graphic below of technologies in the world of Big Data and broadly understood AI.

Source: Matt Turck – Big Data and AI Landscape for 2018
A bit of a shock, isn’t it? Okay, now take it slowly. The points below do not exhaust the topic, and I wanted to show you the direction that data engineering involves.
Methods of storing data
- Database
- media in the public cloud, e.g. S3
- cold/hot storage
- in-memory
An extremely important issue, after all, data must be stored somewhere in order to be processed. Data storage is an important issue because over the years, approaches are evolving, data is growing at an astronomical pace, and something that was once a de facto standard - see relational databases - may not be sufficient in today’s world. It is worth looking at your data processing projects in terms of how we use our data, whether 100% of the data is processed and needed, or maybe I have X% of historical data that we do not process or it would be enough to aggregate it to a higher level and archive the detailed data. Do we want to leverage memory and pump our data to in-memory solutions to increase performance. These and many other similar questions are worth asking in the context of data storage methods.
Retrieving data from source systems
- knowledge of source systems
- relational databases
- non-relational databases
Another important point, where we get the data from. It is not manna from heaven that automatically flows into our systems. In the vast majority of cases, we collect data from our company’s or third-party source systems for storage and further processing. There may be many such systems, and they often differ significantly in their structure and the form in which they expose data for further processing. From a system with relational structures, where knowledge of the schema and how relationships and attributes are used in the system is important. After a non-relational source, where information about the amount of data that is created in a given unit of time and whether their entire scope should be involved in further processing may be important.
Data processing methods
- ETL/ELT processes
- “batch” processing
- streaming processing
- working with metadata
- taking care of data quality
Data processing methods are the heart of the system. In addition to the methods of data processing such as ETL (Extract - Transform - Load) or ELT (Extract - Load - Transform) processes and the types of their processing - batch or stream processing, an equally important (if not the most important) issue is the quality of data and metadata. It is often these last two issues that determine whether end users will trust us or rather “box in” and question what we provide them.
Architecture of data processing systems
- traditional data warehouse based on a batch system
- data lake
- combination of batch system and data streaming (Big Data systems)
As I mentioned above, when it comes to data storage, the amount of data is growing at a dizzying pace and this trend does not seem to reverse in the future (on the contrary). The architectures of data processing systems, which until recently were the benchmark and responded to all business needs (see traditional data warehouses and batch processing), are now often no longer sufficient. With the growth of data and the desire to have business knowledge in almost real time, the system architecture had to change.
Infrastructure supporting data engineering
- public cloud
- local servers (on-premise)
- hybrid solutions
- virtualization / containerization
Keeping a desktop computer under the desk as a server storing company data will not work 🙂 Public cloud is becoming a new standard, and more and more companies decide to switch from the so-called on-premise (managed and kept within the enterprise) to move to the cloud. As with everything, here we can encounter advantages and disadvantages of such a solution. Therefore, before making a hurray optimistic entry into the cloud, it is worth considering the decision, calculating the costs, and checking whether all or some of the company’s systems will be transferred. If so, will this part have an impact on performance, e.g. source systems in the cloud versus analytics on the company’s local servers? Do we have the competences to enter the world of the cloud or do we have to create them (or invite external companies to help us). These are not easy and simple decisions, so a card, a pencil, pluses, minuses and then the decision. Here are some statistics about the use of “cloud” solutions: https://hostingtribunal.com/blog/cloud-computing-statistics/#gre
Analytics and visualization
Since we have downloaded and processed the data, it would be a good idea to present it in a neat form so that we can take real business action based on it, after all, that is our goal 🙂 At this point, as in the others, the issue to consider is whether we want a visualization/analytics layer create ourselves based on our own solution or maybe we will use solutions available on the market, which again comes down to considerations: which supplier, price, limitations, etc.
Ok ok, probably a bit too many of these topics. So you’re telling me that I need to know all this to be a data engineer? It depends 🙂 mainly on the scale. If the scale of the data processing project is small, you can easily cope with each of the above elements. Of course, you don’t always have to like it - monitoring and administering tools instead of using them - but it is an option. However, in general, I would look at it from a more common sense perspective.
As I mentioned earlier, IT is a broad field that can be divided into many groups. It’s similar with data engineering, which we can easily divide.
Data Engineering split into Fields
System Architecture
The world does not stand still, practically every week we hear about new tools or new services available from one of the cloud solution providers. Keeping up with the latest developments, testing, checking and validating tools in addition to your normal daily work can be quite difficult. It is worth considering a role whose main goal will be to select the best possible tools and system design for the problem we want to solve. This doesn’t mean that if you want to focus on data processing and business logic, you have to lock yourself in the basement :) Let’s spend time learning and discovering new things, that’s clear. However, a consistent vision, process improvement and approach applied to the solution will ensure greater success.
Reliability of tools and components
The tools and technologies you use every day have their own features and requirements, and sometimes they may break down. Technologies like Hadoop, Apache Spark, Apache Airflow, or any other are not managed by the invisible hand of an administrator. Someone has to install them, configure them appropriately and monitor resource consumption to see if SELECT * kills the machine they are working on. Such a task is non-trivial, time-consuming and often requires combining many disciplines. From good knowledge of operating systems, through containerization or virtualization technologies, through network layers, to the process of identity identification and access to resources. And again, it’s not about you sitting in a golden cage and not being interested in it at all. If you use a given technology, it would be at least decent to know what its architecture is (i.e. what components it uses so that you can use it), what the most common problems are and how they can be diagnosed.
Data Processing
And then we have the meat – data processing.
- How many data sources can be combined together and extract business information from them?
- How to ensure the quality of processing processes and the data themselves?
- How to ensure that data is available as quickly as possible?
Data engineering answers these and many other questions. It is not only about preparing appropriate data processing processes, but also ensuring quality, repeatability and the best possible solution to potential business questions. Here you can write everything by hand, or you can use graphical user interfaces. Often, it will be necessary to discuss with source system experts to determine the structure, the best way of retrieving data or its quality in the context of what the target customer wants to receive. It will also depend on you whether the analytical/visualization layer will have more work on its side, e.g. building and creating business metrics, or whether it will be possible to consolidate it in the data layer and data model.
Analytics and Visualization
Whether we make analytics and visualization part of the data processing process is a matter of convention. Personally, I am of the opinion that this should be a separate part of the process that closely cooperates both with business clients and also with people responsible for providing reliable data in the form in which it was agreed.
As a person who knows business and key issues very well, I do not necessarily need to know that sales data comes from 8 different source systems with such and such structures. I would rather focus on the most accurate answer to the business problem. This will be related to a conversation about a good way to provide data (e.g. aggregating data to a certain level), sensible data refreshing (maybe data is not needed with an accuracy of up to X seconds), data quality (i.e. what we expect at the output and what to do in a situation where we do not have it), but also (or perhaps primarily) on preparing the analytical layer / data visualization so that the recipient can work with it freely.
Let’s try to name the roles in these groups. The titles are conventional, as I mentioned earlier, they do not have much significance, but they will make it easier for us to associate the groups described above:
- Architecture: Data Architect
- Tools, processes, reliability: Data Reliability Engineer / DevOps Engineer (Data Tools)
- Data Processing/Engineering: Data Engineer
- Analytics, visualization: Data Analyst / Data Visualization Specialist / Business Intelligence Developer
What “technology” does each role touch?
If you expect that we will nicely separate technologies and roles here, I think you will be surprised. The technologies themselves are not very important, they change from time to time and will basically be common to each role with a few exceptions.
What does it mean that they will be common to each role? This means only (or as much as) that the database will be important for both the architect, devops, data engineer and analyst. However, for each of these people it will be important in a different context. This context may be the fact what the limits of a given product are. From the architect’s perspective (specific operating system, lack of containerization, etc.). For a data engineer, it may be whether there is any significant limit in data processing for a given product/technology etc.
However, in order not to be false, in the introduction I promised to present you “hot” technologies, so let’s try:
- Programming language (depending on specific technologies): Python, SQL
- Message Queues: Apache Kafka
- Data flows: Apache Airflow
- “General Purpose”: Apache Spark (Streaming, SQL, In-Memory Computing)
- Databases: PostgreSQL, Redis, Cassandra, Neo4j
- Services of cloud providers, e.g. data warehouses: Snowflake (cloud data warehouse based on the infrastructure of the selected AWS / Azure / Google Cloud provider) or Amazon Redshift, Google Big Query, Azure Synapse Analytics
- Others: Docker (containerization), Jenkins (process automation), Kubernetes (the key word must be used in a decent article, but seriously, for website management),
- Analytics / Visualizations: Qlik Sense
Forgive me, but I will not describe each of these technologies. Google will definitely come to your aid in this matter. The technologies above are just my purely subjective choice - I don’t make any money from it. If you work with other technologies in the areas mentioned above, super will definitely do the job too.
Summary
To the shore Krzysiek to the shore, it’s time to slowly summarize. In this article I showed you my path from scraping SELECTs to becoming a Data Engineer. But is the name of the role itself the key here? After reading this text, I would like the answer to be no.
The goal is more important, and data engineering has one (well, maybe not one, but the most important one).
Provide data in such a way that you can take action based on it (and not have to wait a week for the data).
You already know that there are quite a lot of groups or elements of working with data, and even more technologies. In order not to get completely lost in the maze of these elements, it is worth paying attention to the basic things:
Source systems for our project – it is worth knowing their structure and architecture
– Well, I take SELECT * and pack it to the wholesaler…
– 320 attributes in the source table, 300 not used in the source because they bought the product from a box and do not use…
- OK
Effective ways of storing data - tailored to the needs of the project (bear in mind that you do not need all the data all the time, and although storage is relatively cheap, it still generates costs);
– But don’t you worry, storage is cheap
– cost of S3 – $0.023 per GB / month, Glacier – $0.004 per GB / month, we have 50 TB of historical data that we do not query 50 * 1024 * 0.023 – $1177.6 vs 50 * 1024 *0.004 – $204.8, come on $1k from your salary like cheap storage
Knowledge of tools that help you in your work - it’s great that you know how to work with a given tool, and do you also know what problems you may encounter along the way, what can go wrong or what to pay attention to?
– Well, if the server is down, is it my fault? After all, it’s in-memory… it’s supposed to work in memory
Logical and clear ways of data processing - there may be many steps in data processing, but if you cannot clearly determine the path from the source to the final result, something is probably too complicated somewhere
– Well, you see, we take it from the source. Next we have tool A for the “staging” layer. Then the transformation in the procedure, we continue to load data into the BI tool. There are 2 transformations and there is this graph
– Hmm .. so how is this metric Month to Month Sales Difference calculated?
– Well, I told you…
Working with data is most often about working in a team - an egoistic approach to work may be good for a short while. However, as a team, we are preparing for a marathon;
– I’ll write Huehue here, a quick script in Go, I’ve always wanted to learn.
– Andrzej, who wrote this script for loading data into a slowly variable dimension in Go? There is some error and nothing is known about it…
Knowledge of how your tools and processes work and the quality of data at each stage;
– Why do I have the value Poland in the Region field 6 times and each element looks different?
– Well… this data came from the source…
Analytics, thanks to which you do not have to wonder whether the results are correct and check them in other systems;
– Total sales for the last quarter are $100,000. Team B’s tool says $96,699, so wait, do you have other data?
This much (or as much) as an answer to the question of what data engineering is. I hope you found this interesting, and if you have any questions, please leave them in a comment below.
Thanks,
Krzysztof
Want to be up to date with new posts?
Use below form to join Data Craze Weekly Newsletter!